Understanding Convolutional Neural Networks From Scratch
A comprehensive guide to CNNs: architecture, forward pass, backpropagation, and practical implementations
Table of Contents
1. Introduction
Convolutional Neural Networks (CNNs) represent a revolutionary approach in deep learning that has transformed computer vision and image processing. Inspired by the organization of the animal visual cortex, CNNs have become the cornerstone of many modern applications including image recognition, object detection, facial recognition, and medical image analysis.
The power of CNNs lies in their ability to automatically learn hierarchical patterns in data, starting from simple features like edges and textures to more complex structures like shapes and objects. Unlike traditional neural networks, CNNs maintain spatial relationships in data, making them particularly effective for processing grid-like structures such as images.
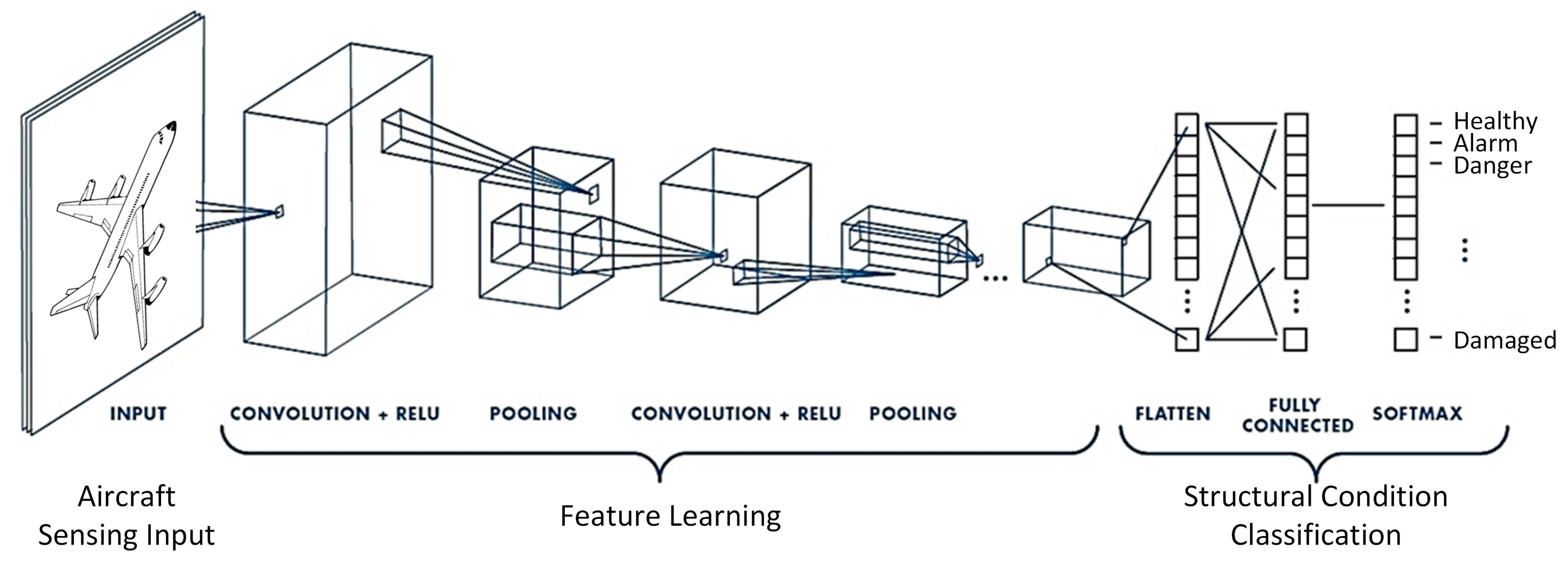
2. What Are Convolutional Neural Networks?
Convolutional Neural Networks (CNNs) are a class of deep learning models specifically designed for processing grid-like data, such as images. At their core, CNNs are stacks of convolutional operations interspersed with non-linear activation functions and pooling layers. These layers work together to extract hierarchical features from the input data, enabling the network to learn spatial patterns efficiently.
Before we explain the key components of a CNN, I believe it's really important that we understand some core concepts of CNNs which are often overlooked in courses, and other blogs.
Key Concepts
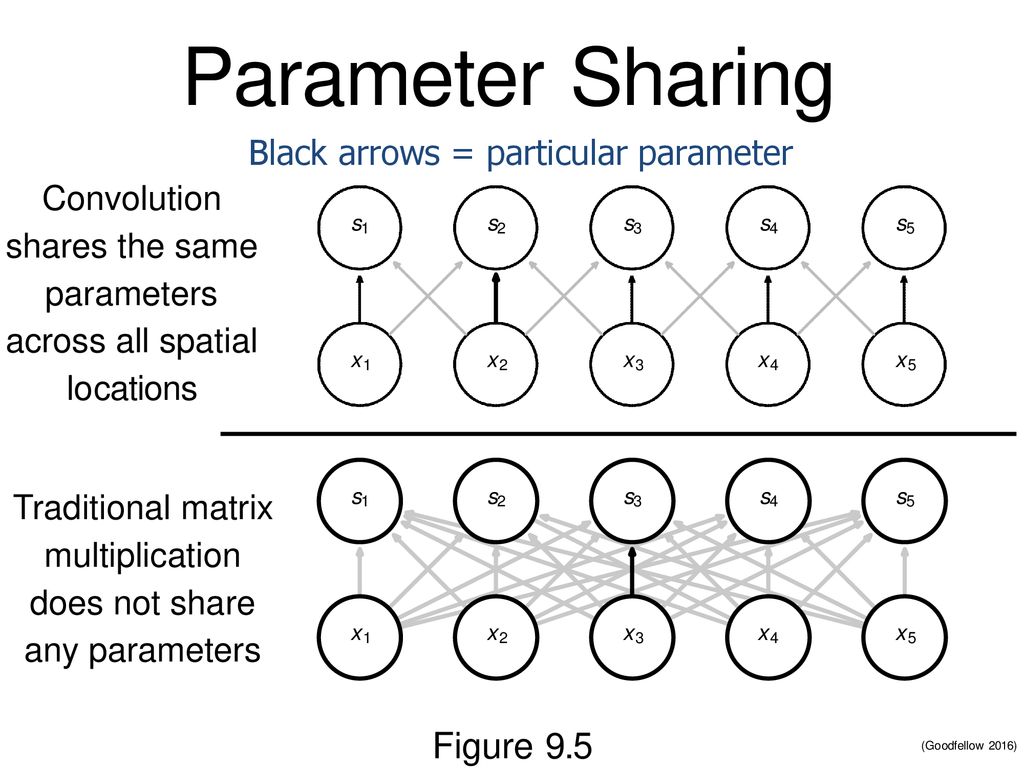
- Parameter Sharing:
Before CNNs, fully connected neural networks(MLPs) were used for image processing, but they had two major problems:
- Too many parameters: Fully connected layers treats each pixel independently, meaning that a simple 32×32×3 image would have 3072 input neurons. If the first hidden layer has 1000 neurons, that results in about 3 million parameters !
- Loss of Spatial Structure: MLPs do not capture the spatial relationships between nearby pixels, treating a pixel at (2, 3) as completely independent from one at (2, 4). But human vision does not process each pixel uniquely. We are naturally able to perceive spatial relationships between pixels, our brain groups nearby pixels to recognize edges, shapes, and textures. We don't process each pixel separately;instead, we recognize patterns that emerge from neighboring pixels.
Instead of learning a unique weight for each input pixel(as in an MLP), CNNs reuse the same set of weights (a kernel or filter) across the entire image. This means that a small kernel slides over the image and applies the same weights at each position.
The same feature detector(kernel) is applied everywhere, meaning the same set of parameters detects the same feature across the image.
We will have a better understanding of these operations in the next section when we will talk about Convolutions
3. Key Components of a CNN
a) Convolutional Layers
The convolution operation is the backbone of CNNs. It involves sliding a small filter (kernel) over the input image and computing the dot product between the filter and the input region.
Let's see how this works with an example!
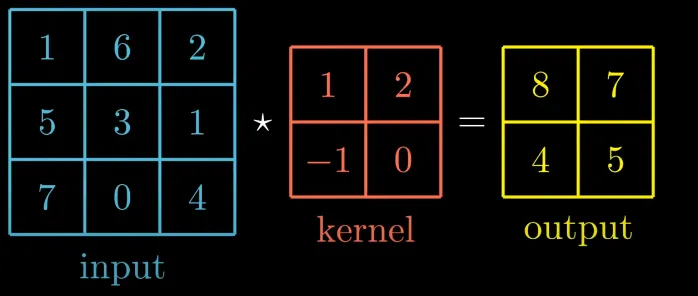
The output matrix is obtained by sliding the kernel over the input one pixel at a time (stride = 1) and computing the dot product between the filter and the input region corresponding. Let's see how this is done.
In the first step the input region is [[1, 6], [5, 3]] and the kernel is [[1, 2], [-1, 0]], the result when we compute the dot product is: 1 * 1 + 6 * 2 + 5 * (-1) + 3 * 0 = 8 . This process repeats itself for each region of the input image.Key Parameters:
- Kernel Size: The size of the filter (e.g., 3x3, 5x5).
- Stride: The step size by which the filter moves across the input (e.g., stride=1 moves the filter one pixel at a time).
- Padding: When an image passes through convolutional layers, its spatial dimensions typically shrink. As an illustration, you can look at our previous example. So after each conv layer, the size of our image usually decrease. However, shrinking the image too quickly can cause problem like loss of information. The network might also suffer to learn features at the edge effectively. To address these issues, we use padding. Padding involves adding extra pixels(usually zeros) around the border of the input image before applying the convolution operation. It helps us capture edge information, preserve spatial dimensions, and thus enable deeper networks.
Convolution Visualization
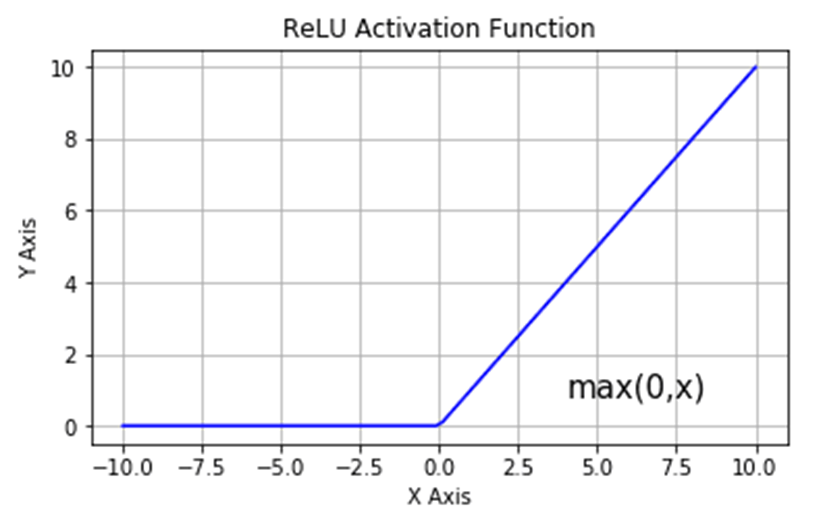
b) Non-linear Activation Functions
After the convolution operation, a non-linear activation function is applied to introduce non-linearity into the model. The most common activation function is ReLU (Rectified Linear Unit) Non Linearities create non linear decision boundaries, this ensure the output cannot be written as a linear combination of the inputs. If non linear activation was absent, deep CNN architectures would be equivalent to a single conv layer, which would not perform as well. I have also learned when i was reading AlexNet paper that ReLU is also faster than other non-linearities.
c) Pooling Layers
Pooling layers reduce the spatial dimensions of the feature maps, making the network more computationally efficient and invariant to small translations. They operate on small regions of the feature map (e.g., 2x2 or 3x3 windows) and apply a pooling operation to summarize the information in that region.
Types of Pooling:
- Max Pooling: Takes the maximum value in each pooling region.
- Average Pooling: Takes the average value in each pooling region.
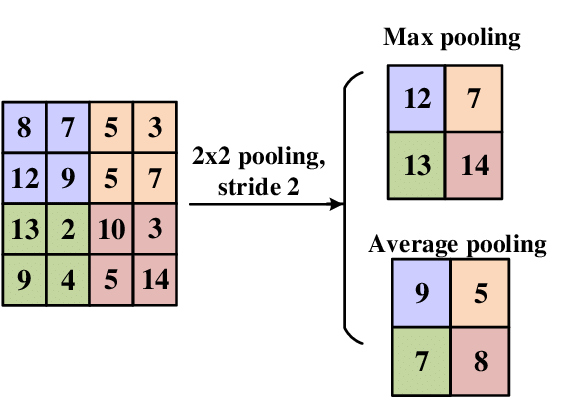
Here the pooling region is 2x2 we apply the operation each time with a stride of 2. For the Max Pooling we take the maximum of the pooling region, for average we take the average.
d) Fully Connected Layers
After several convolutional and pooling layers, the output is flattened and passed through one or more fully connected layers. These layers combine the extracted features to produce the final output (e.g., class probabilities, continuous value).
4. Exercise: Calculating Output Dimensions in AlexNet
Let’s walk through an example to understand how the dimensions of an input image change as it passes through a CNN. Consider AlexNet, a classic CNN architecture:
AlexNet Architecture:
- Input: 227x227x3 (height x width x channels)
- Conv1: 96 filters of size 11x11, stride=4, padding=0
- MaxPool1: 3x3, stride=2
- Conv2: 256 filters of size 5x5, stride=1, padding=2
- MaxPool2: 3x3, stride=2
- Conv3: 384 filters of size 3x3, stride=1, padding=1
- Conv4: 384 filters of size 3x3, stride=1, padding=1
- Conv5: 256 filters of size 3x3, stride=1, padding=1
- MaxPool3: 3x3, stride=2
- Fully Connected Layers: 4096, 4096, 1000 (output classes)
Formula to Calculate Output Dimensions:
Step-by-Step Calculation:
- Conv1: (227 - 11) / 4 + 1 = 55 → Output: 55x55x96
- MaxPool1: (55 - 3) / 2 + 1 = 27 → Output: 27x27x96
- Conv2: (27 - 5 + 2×2) / 1 + 1 = 27 → Output: 27x27x256
- MaxPool2: (27 - 3) / 2 + 1 = 13 → Output: 13x13x256
- Conv3: (13 - 3 + 2×1) / 1 + 1 = 13 → Output: 13x13x384
- Conv4: (13 - 3 + 2×1) / 1 + 1 = 13 → Output: 13x13x384
- Conv5: (13 - 3 + 2×1) / 1 + 1 = 13 → Output: 13x13x256
- MaxPool3: (13 - 3) / 2 + 1 = 6 → Output: 6x6x256
- Fully Connected Layers: Flatten the output (6x6x256 = 9216) and pass it through the fully connected layers.
5. Training a CNN: Forward Pass
Now let's train a small CNN by hand to make sure we understand everything properly
- Input: A 4x4 grayscale image
- Convolution: 1 filter of size 2x2, Stride = 1, no padding.
- Activation: ReLU
- Pooling: Pool size 2x2, Stride = 2
- Fully Connected Layers: 02 neurons, activation function will be Softmax, we will do a simple binary classification
- Loss Function Cross Entropy Loss
- The activation map \(A\) is already 2x2, so max pooling doesn’t change it: \[ P = \begin{bmatrix} 0 & 0 \\ 0 & 0 \end{bmatrix} \] Fully Connected Layer
- Flatten \( P \) into a vector: \([0, 0, 0, 0]\). - Let’s say the weights \( W_{fc} \) and biases \( b_{fc} \) are: \[ W_{fc} = \begin{bmatrix} 0.1 & 0.2 \\ 0.3 & 0.4 \\ 0.5 & 0.6 \\ 0.7 & 0.8 \end{bmatrix}, \quad b_{fc} = \begin{bmatrix} 0.1 \\ 0.2 \end{bmatrix} \] - Compute the output: \[ Z = W_{fc}^T \cdot P + b_{fc} = \begin{bmatrix} 0.1 \\ 0.2 \end{bmatrix} \] - Apply softmax to get probabilities: \[ \text{Softmax}(Z) = \begin{bmatrix} 0.475 \\ 0.525 \end{bmatrix} \] Loss Calculation
- True label: \( y = [1, 0] \) so it' class 0). - Cross-entropy loss: \[ \begin{align*} L=-\sum y_i\log(p_i)=-\log(0.475)\approx 0.744 \end{align*}
6. Training a CNN: Backward Pass
Now let's compute the backward pass and update the weights. It can seems tricky but it's not:a) Gradient of the Loss w.r.t. Fully Connected Layer - Softmax derivative: \[ \frac{\partial L}{\partial Z} = \text{Softmax}(Z) - y = \begin{bmatrix} 0.475 & -1 \\ 0.525 & 0 \end{bmatrix} = \begin{bmatrix} -0.525 \\ 0.525 \end{bmatrix} \] - Gradient of \( W_{fc} \): \[ \frac{\partial L}{\partial W_{fc}} = P \cdot \frac{\partial L}{\partial Z} = \begin{bmatrix} 0 & 0 \\ 0 & 0 \end{bmatrix} \cdot \begin{bmatrix} -0.525 \\ 0.525 \end{bmatrix} = \begin{bmatrix} 0 & 0 \\ 0 & 0 \end{bmatrix} \] - Gradient of \( b_{fc} \): \[ \frac{\partial L}{\partial b_{fc}} = \frac{\partial L}{\partial Z} = \begin{bmatrix} -0.525 \\ 0.525 \end{bmatrix} \] b)Gradient of the Loss w.r.t. Convolutional Layer --we propagate gradients through max pooling (no change since pooling gradients are passed to the max value locations). After that through the ReLU(gradient is 0 for non-positive inputs) - Gradient of \( W \): \[ \frac{\partial L}{\partial W} = \sum_{\text{positions}} \frac{\partial L}{\partial A} \cdot X_{\text{patch}} \] Since \(\frac{\partial L}{\partial A} = 0\) (all activations are 0), the gradient of \( W \) is also 0.
c) Weight Updates - Update \( W_{fc} \) and \( b_{fc} \) using the gradients and a learning rate of \(\eta = 0.1\): \[ W_{fc} = W_{fc} - \eta \cdot \frac{\partial L}{\partial W_{fc}} = W_{fc} - 0.1 \cdot \begin{bmatrix} 0 & 0 \\ 0 & 0 \end{bmatrix} = W_{fc} \] \[ b_{fc} = b_{fc} - \eta \cdot \frac{\partial L}{\partial b_{fc}} = \begin{bmatrix} 0.1 \\ 0.2 \end{bmatrix} - 0.1 \cdot \begin{bmatrix} -0.525 \\ 0.525 \end{bmatrix} = \begin{bmatrix} 0.1525 \\ 0.1475 \end{bmatrix} \] That's it!
7. Building a CNN in PyTorch
So far, we have talked about the theory of CNN, we have trained one by hand, the next step is to code one. For that we will use Pytorch. The Architecture that we will implement is AlexNet (already described in the previous sections).
We will simply stop at the architecture level. To see all the code required for training you can check out my my repo
from torch import nn
class AlexNet(nn.Module):
def __init__(self):
super().__init__()
self.feature_extraction = nn.Sequential(
nn.Conv2d(3, 96, 11, stride = 4),
nn.ReLU(),
nn.MaxPool2d(3, stride = 2),
nn.Conv2d(96, 256, 5, stride = 1, padding = 2),
nn.ReLU(),
nn.MaxPool2d(3, stride = 2),
nn.Conv2d(256, 384, 3, stride = 1, padding = 1),
nn.ReLU(),
nn.Conv2d(384, 384, 3, stride = 1, padding = 1),
nn.ReLU(),
nn.Conv2d(384, 256, 3, stride = 1, padding = 1),
nn.ReLU(),
nn.MaxPool2d(3, stride = 2)
)
self.flatten = nn.Flatten()
self.fc1 = nn.Linear(9216, 4096)
self.dropout = nn.Dropout(p = 0.5)
self.fc2 = nn.Linear(4096, 200)
def forward(self, x):
x = self.feature_extraction(x)
x = self.flatten(x)
x = self.fc1(x)
x = nn.ReLU()(x)
x = self.dropout(x)
x = self.fc2(x)
return x
I won’t explain the code in detail because I believe it’s pretty straightforward. Each element is named according to its purpose, making it easy to understand.
That's all from me! I hope you enjoyed the blog and learned something new. If you have any questions, feel free to reach out to me on Twitter / X